
Data Lake with AWS: Governance, Scalability and Insights in the Cloud
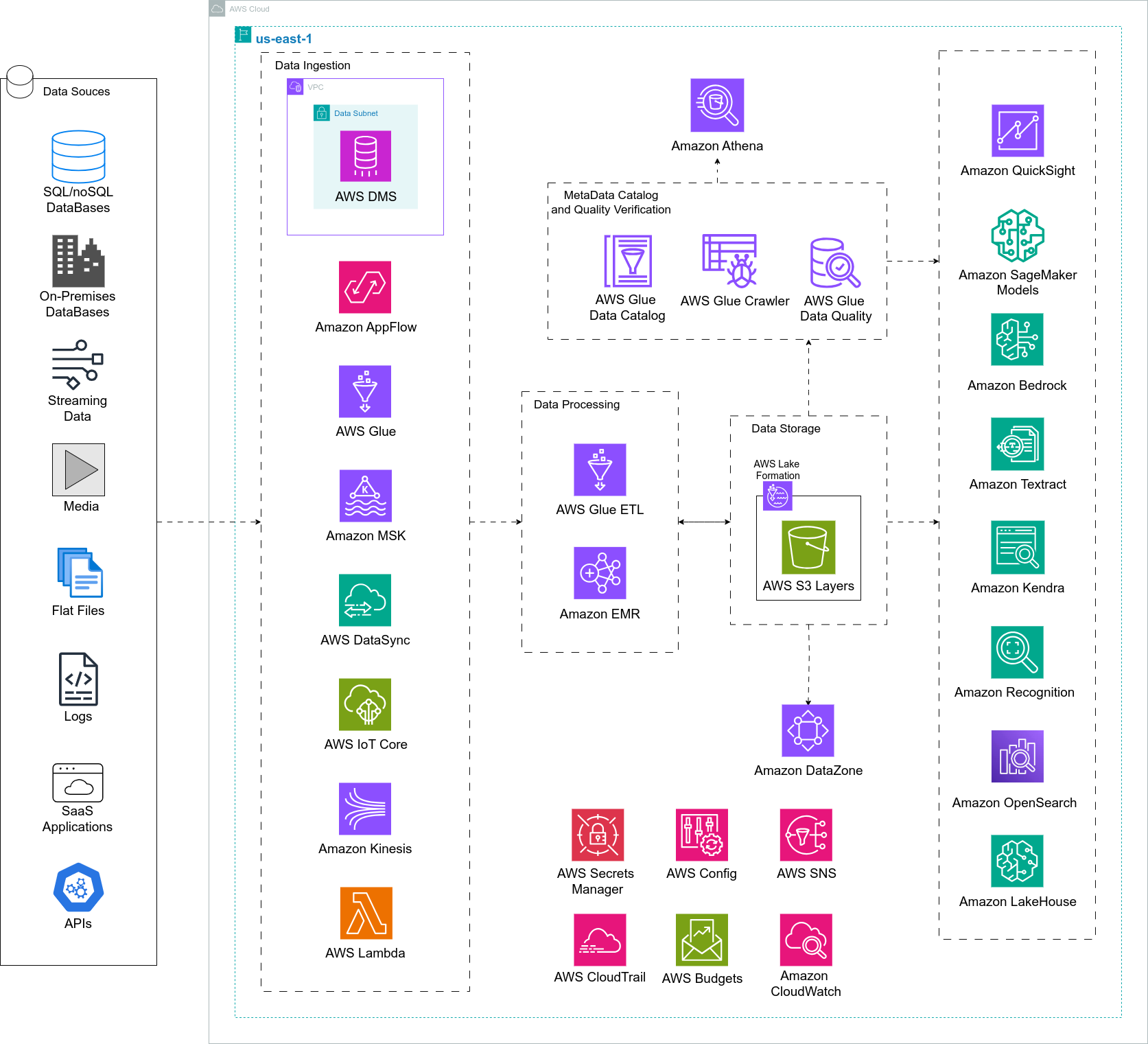
CloudDog offers a highly efficient Data Lake solution that leverages the powerful AWS Cloud services to streamline data organization and analysis. Our architecture includes AWS Lake Formation for centralized and secure data catalog management, ensuring robust governance and simplified discovery. We use S3 for storage, Glue for ETL, Athena for queries, and Step Functions with EventBridge for automation.
Features
- AWS Lake Formation for Centralized Governance: Enables efficient and secure Data Lake management, with granular access control, activity monitoring, and regulatory compliance, ensuring a trustworthy environment for data storage and analysis.
- Amazon S3 with Layered Structure: The scalable and secure storage of Amazon S3 is organized into Bronze, Silver, and Gold layers, allowing ingestion of raw data, intermediate transformations, and optimizations for strategic analyses. This structure promotes operational efficiency and accessibility for various teams.
- AWS Glue for ETL Pipelines: Provides advanced transformations and automation of ETL processes, ensuring that data is prepared for real-time analysis and strategic reporting. The solution includes partitioning and compression to maximize performance.
- Amazon Athena for Scalable Queries: Offers fast and reliable queries directly in the Data Lake, enabling ad hoc analyses and critical decision support, all without needing to provision additional infrastructure.
- AWS Step Functions and Amazon EventBridge for Automated Orchestration: Automates data processing workflows, ensuring that the different stages of the pipeline are executed reliably, scalably, and monitored.
- AWS DMS for Data Migration: Ensures secure and efficient data transfer from on-premises or other cloud databases to the AWS Data Lake, using a VPN Site-to-Site for enhanced security and reliability.
- Glue Data Catalog for Data Discovery: Centralizes and organizes the Data Lake metadata, facilitating the discovery, classification, and usage of data by different tools and teams, promoting reuse and efficient management.
- AWS Secrets Manager for Secure Credential Management: Simplifies the management and protection of credentials and secrets required for integration with external systems and data sources, ensuring compliance and connection security.
- Amazon EMR for Advanced Data Processing: Amazon EMR enables you to run big data frameworks such as Apache Spark, Hadoop, and Presto directly on data stored in the Data Lake. It is ideal for complex analytics, machine learning, and distributed workloads, and automatically scales to efficiently manage large clusters.
- Machine Learning and Amazon SageMaker Integration: The Data Lake, organized into tiers (Bronze, Silver, and Gold), provides a robust foundation for training machine learning models on Amazon SageMaker. Native integration with services such as AWS Glue DataBrew makes it easy to prepare data for predictive and prescriptive analytics, while Amazon Forecast and Amazon Comprehend can be used to create predictive insights and advanced text analytics.
AWS Partner and AWS Certified Partner
CloudDog's journey began in 2019 when the company achieved the AWS Select Partner tier. Since then, it has maintained a total focus on the Amazon Web Services ecosystem. Over the following years, the team earned several key certifications, standing out in 2020 by becoming the second partner in Brazil to be validated for Amazon CloudFront.
The major milestone of this evolution came in 2023, when the company upgraded to AWS Advanced Partner Tier, a direct result of its technical expertise and the successful delivery of over 100 cloud projects.
Today, CloudDog has reached a new level of technical maturity. The company now holds four AWS Competencies (SMB, Cloud Operations, AI Services, and DevOps Consulting) and 14 Service Validations (SDPs), covering essential tools like Control Tower, EKS, Lambda, and databases. To further strengthen its end-to-end capabilities, CloudDog joined the Well-Architected program and earned the rigorous AWS Managed Service Provider (MSP) validation, proving its excellence in the continuous management and support of cloud environments.
Currently, CloudDog is fully prepared to support companies through every stage of their technological journey. Backed by a team holding all AWS certifications, the company handles everything from workload migrations to daily environment support and optimization. These achievements serve as practical proof of CloudDog's position as a trusted consultancy, focused on delivering solid, secure, and high-quality results.
Arquitetura
For this solution, we provide case-specific architectures, offering alternatives to typical Data Lake implementations with varying levels of scalability, cost efficiency, and process automation. Each architecture is designed to address specific use cases, including data ingestion via APIs, integration with external databases, highly complex scenarios with advanced governance, and real-time data streaming.
Use Case
- Data Lakes for High-Volume Processing: Perfect for companies managing large data volumes, such as banks, insurers, or industries with multiple data sources.
- Analytics for Strategic Decision-Making: Ideal for organizations that need optimized and ready-to-use data for fast analysis, such as BI companies or marketing departments using machine learning to predict trends.
- Storage and Processing of Complex Data: Great for scenarios requiring the processing of heterogeneous and unstructured data, such as system logs, media files, or large datasets used in scientific research.
- Storage and Processing of Real-Time Data: Excellent for scenarios that require real-time data capture, processing, and storage, such as clickstream, video stream, log stream, and others.
- Data Compliance and Security: Essential for organizations that must comply with strict regulations like GDPR, LGPD, or HIPAA, ensuring the protection of sensitive data and the implementation of robust access controls. Ideal for sectors like healthcare, finance, and government, where data governance and auditing are crucial.
- Machine Learning and Artificial Intelligence: Essential for companies that want to explore predictive and prescriptive analytics, using data organized in the Data Lake to train machine learning models. The Data Lake serves as the basis for AI solutions in areas such as content personalization, demand forecasting, and sentiment analysis. With integration with services such as Amazon SageMaker, it is possible to develop and deploy models directly on the stored data.
Frequently Asked Questions
What security measures are implemented to protect the Data Lake?

Encryption with AWS KMS, granular access control via IAM, and monitoring with CloudTrail are used to ensure auditability and compliance.
Can the Data Lake be configured for real-time data processing?
Yes, with services like Amazon Kinesis and AWS Glue Streaming, the Data Lake supports real-time processing for large data volumes.
How does AWS DMS facilitate data ingestion into the Data Lake?
AWS DMS migrates data from on-premises or cloud databases to the Data Lake on S3, ensuring secure and efficient transfer.
How does the Data Lake support Machine Learning?
The Data Lake organizes data into optimized tiers (Bronze, Silver, and Gold), allowing data from the Gold tier to be used directly to train models in services like Amazon SageMaker. It also integrates with Glue DataBrew for data preparation and Amazon Forecast for time-series-based forecasting, ensuring that data is ready for advanced analytics.
How does AWS Glue optimize data processing in the Data Lake?
AWS Glue not only automates ETL tasks, it also provides a fully managed platform that lets you build complex pipelines without having to provision servers. It supports multiple data formats (such as Parquet, JSON, and CSV) and includes a built-in Data Catalog that makes it easy to discover and organize data. Glue is also highly scalable, allowing you to efficiently perform transformations on large volumes of data. It also natively integrates with other AWS services, such as Lake Formation and Athena, providing a unified experience.
How can Amazon EMR help you process data in a Data Lake?
Amazon EMR is ideal for processing large volumes of data using frameworks such as Apache Spark and Hadoop. It allows you to run big data workloads directly in the Data Lake, using native integration with Amazon S3. In the case of a Data Lake, EMR is especially useful for complex analytics such as machine learning and distributed queries on very large datasets, and it offers the elasticity to scale clusters on demand.
What is AWS Lake Formation, and how does it help with data governance?
AWS Lake Formation centralizes data cataloging and access control in the Data Lake, ensuring security and compliance with regulations such as LGPD and GDPR. It allows you to configure role-based permissions (RBAC) to access specific tables and columns, making it easier to enforce detailed security policies. Lake Formation also simplifies metadata management, enabling faster data discovery and use.
How does integrating with Amazon Athena benefit data queries?
Amazon Athena allows executing SQL queries directly on the Data Lake without provisioning infrastructure, making access fast and efficient.
Can AWS Step Functions orchestrate processes in the Data Lake?
Yes, AWS Step Functions automate and organize data pipelines, coordinating workflows between ingestion, processing, and storage in layers.
Talk to Our
Experts in Cloud
Contact us and find out how we can help your
company reduce costs on AWS Cloud.
