
Data Lake com AWS: Governança, Escalabilidade e Insights na Nuvem
A CloudDog apresenta uma solução de Data Lake de alta eficiência, aproveitando os poderosos serviços da Nuvem AWS para otimizar a organização e análise de dados. Nossa arquitetura inclui o AWS Lake Formation para uma gestão centralizada e segura do catálogo de dados, garantindo governança robusta e descoberta simplificada. Usamos S3 para armazenar, Glue para ETL, Athena para consultas e Step Functions com EventBridge para automação.
Características
- AWS Lake Formation para Governança Centralizada: Permite a gestão eficiente e segura do Data Lake, com controle de acesso granular, monitoramento de atividades e conformidade com regulamentações, garantindo um ambiente confiável para armazenamento e análise de dados.
- Amazon S3 com Estrutura em Camadas: O armazenamento escalável e seguro do Amazon S3 é organizado nas camadas Bronze, Silver e Gold, permitindo a ingestão de dados brutos, transformações intermediárias e otimizações para análises estratégicas. Essa estrutura promove eficiência operacional e acessibilidade para diversas equipes.
- AWS Glue para Pipelines ETL: Fornece transformações avançadas e automação de processos ETL, garantindo que os dados estejam preparados para análises em tempo real e relatórios estratégicos. A solução inclui particionamento e compactação para maximizar a performance.
- Amazon Athena para Consultas Escaláveis: Oferece consultas rápidas e confiáveis diretamente no Data Lake, permitindo análises ad hoc e suporte a decisões críticas, tudo sem necessidade de provisionar infraestrutura adicional.
- AWS Step Functions e Amazon EventBridge para Orquestração Automatizada: Automatizam o fluxo de processamento de dados, assegurando que as diferentes etapas do pipeline sejam executadas de maneira confiável, escalável e monitorada.
- AWS DMS para Ingestão de Dados: Garante a transferência segura e eficiente de dados de bancos de dados locais ou de outras nuvens para o Data Lake na AWS, utilizando VPN Site-to-Site para maior segurança e confiabilidade.
- Glue Data Catalog para Descoberta de Dados: Centraliza e organiza os metadados do Data Lake, facilitando a descoberta, classificação e uso dos dados por diferentes ferramentas e equipes, promovendo a reutilização e o controle eficiente.
- AWS Secrets Manager para Gerenciamento Seguro de Credenciais: Simplifica o gerenciamento e a proteção de credenciais e segredos necessários para integração com sistemas externos e fontes de dados, garantindo conformidade e segurança nas conexões.
- Amazon EMR para Processamento Avançado de Dados: O Amazon EMR permite executar frameworks de Big Data, como Apache Spark, Hadoop e Presto, diretamente nos dados armazenados no Data Lake. Ele é ideal para análises complexas, aprendizado de máquina e cargas de trabalho distribuídas, com escalabilidade automática para gerenciar clusters de grande porte de forma eficiente.
- Machine Learning e Integração com Amazon SageMaker: O Data Lake organizado em camadas (Bronze, Silver e Gold) fornece uma base robusta para o treinamento de modelos de aprendizado de máquina no Amazon SageMaker. A integração nativa com serviços como AWS Glue DataBrew facilita a preparação de dados para análises preditivas e prescritivas, enquanto o Amazon Forecast e o Amazon Comprehend podem ser usados para criar insights preditivos e análises de texto avançadas.
Empresa Parceira
e Certificada AWS
A trajetória da CloudDog começou em 2019, quando a empresa alcançou o nível de Parceiro AWS Select. Desde então, mantém um foco total no ecossistema da Amazon Web Services. Nos anos seguintes, a equipe acumulou diversas certificações importantes, com destaque para 2020, ao se tornar o segundo parceiro no Brasil validado para o Amazon CloudFront.
O grande marco dessa evolução aconteceu em 2023, com a ascensão ao status de parceiro AWS Advanced, resultado da sua capacidade técnica e da entrega bem-sucedida de mais de 100 projetos na nuvem.
Hoje, a CloudDog atinge um novo nível de maturidade técnica. A empresa já soma quatro Competências AWS (SMB, Cloud Operations, AI Services e DevOps Consulting) e 14 validações de serviços (SDPs), cobrindo ferramentas essenciais como Control Tower, EKS, Lambda e bancos de dados. Para fortalecer ainda mais sua atuação de ponta a ponta, a CloudDog passou a integrar o programa Well-Architected e conquistou a difícil validação de AWS Managed Service Provider (MSP), comprovando a excelência na gestão contínua e na sustentação de ambientes em nuvem.
Atualmente, a CloudDog está totalmente preparada para apoiar as empresas em todas as etapas da jornada tecnológica. Respaldada por um time com todas as certificações da AWS, a empresa conduz desde a migração de cargas de trabalho até a sustentação e otimização diária do ambiente. Esses reconhecimentos reforçam de forma prática a posição da CloudDog como uma consultoria de confiança, focada em entregar resultados sólidos, seguros e de qualidade.
Arquitetura
Para esta solução, fornecemos arquiteturas especializadas ao caso, oferecendo alternativas para implementações típicas de Data Lake com níveis variados de escalabilidade, eficiência de custo e automação de processos. Cada arquitetura é projetada para abordar casos de uso específicos, incluindo ingestão de dados via APIs, integração com bancos de dados externos, cenários altamente complexos com governança avançada e fluxo de dados em tempo real.
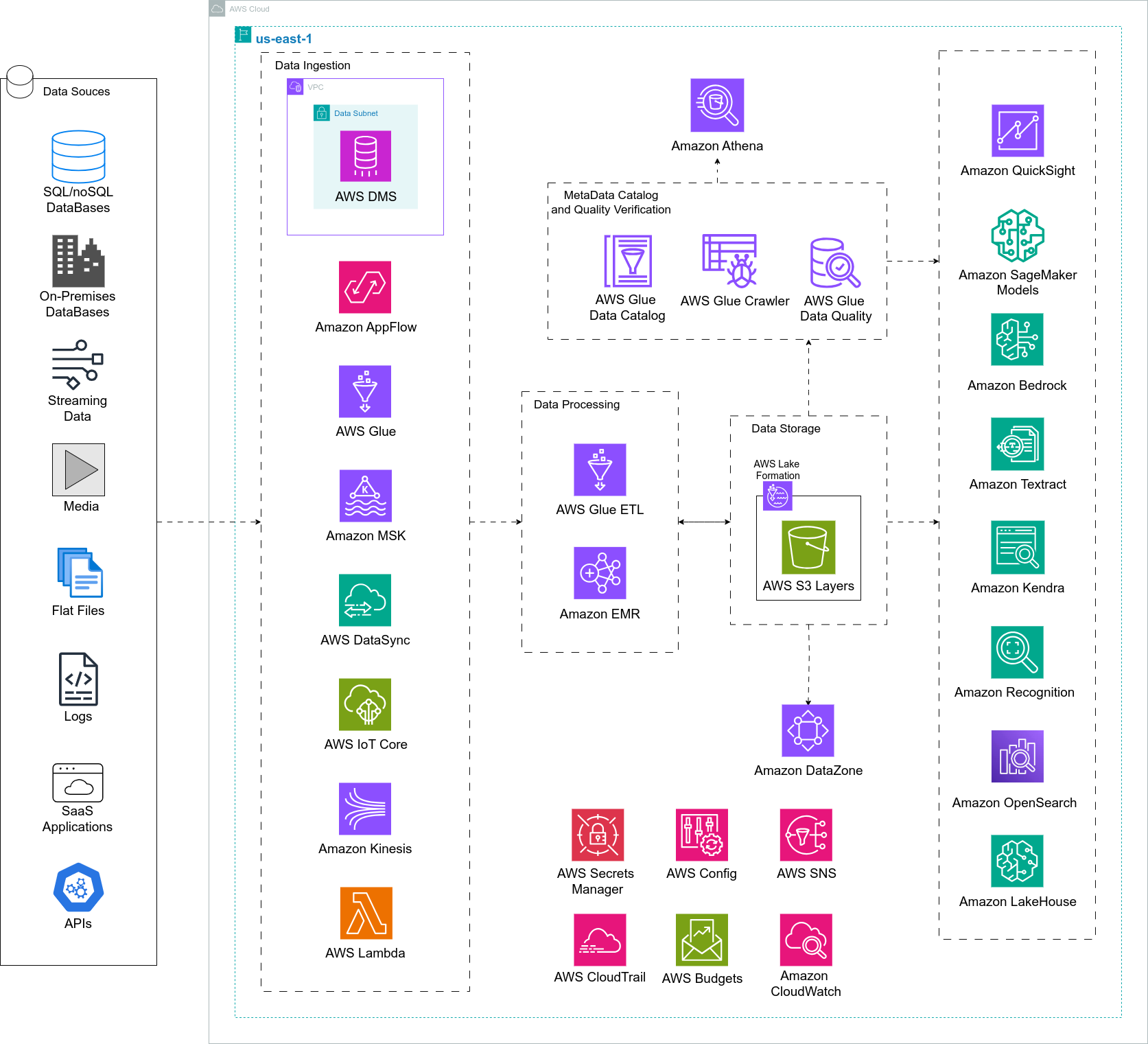
Casos de Uso
- Data Lakes para Processamento de Alto Volume: Perfeito para empresas que gerenciam grandes volumes de dados, como bancos, seguradoras ou indústrias com múltiplas fontes de dados.
- Análises para Decisões Estratégicas: Ideal para organizações que necessitam de dados otimizados e prontos para análises rápidas, como empresas de BI ou departamentos de marketing que utilizam machine learning para prever tendências.
- Armazenamento e Procesamento de Dados Complexos: Ótimo para cenários que exigem o processamento de dados heterogêneos e não estruturados, como logs de sistemas, arquivos de mídia ou grandes datasets usados em pesquisas científicas.
- Armazenamento e Processamento de Dados em Tempo Real: Ótimo para cenários onde é necessário a captação, o processamento e o armazenamento de dados em tempo real, como clickstream, video stream, log stream dentre outros.
- Conformidade e Segurança de Dados: Essencial para organizações que precisam cumprir regulamentações rigorosas, como LGPD, GDPR ou HIPAA, garantindo a proteção de dados sensíveis e a implementação de controles de acesso robustos. Ideal para setores como saúde, finanças e governo, onde a governança e a auditoria de dados são cruciais.
- Machine Learning e Inteligência Artificial: Fundamental para empresas que desejam explorar análises preditivas e prescritivas, utilizando dados organizados no Data Lake para treinamento de modelos de aprendizado de máquina. O Data Lake serve como base para soluções de IA em áreas como personalização de conteúdo, previsão de demanda e análise de sentimento. Com integração a serviços como Amazon SageMaker, é possível desenvolver e implantar modelos diretamente nos dados armazenados.
Perguntas Frequentes
Como o AWS Glue otimiza o processamento de dados no Data Lake?

O AWS Glue não apenas automatiza tarefas de ETL, mas também oferece uma plataforma totalmente gerenciada que permite criar pipelines complexos sem a necessidade de provisionar servidores. Ele suporta múltiplos formatos de dados (como Parquet, JSON e CSV) e inclui um Data Catalog integrado que facilita a descoberta e a organização dos dados. Além disso, o Glue é altamente escalável, permitindo executar transformações de grandes volumes de dados com eficiência. Ele também integra-se nativamente a outros serviços da AWS, como Lake Formation e Athena, promovendo uma experiência unificada.
Como o Amazon EMR pode ser útil para o processamento de dados no Data Lake?
O Amazon EMR é ideal para processar grandes volumes de dados com frameworks como Apache Spark e Hadoop. Ele permite executar cargas de trabalho de Big Data diretamente no Data Lake, usando a integração nativa com o Amazon S3. No caso de um Data Lake, o EMR é especialmente útil para análises complexas, como aprendizado de máquina e consultas distribuídas em datasets muito grandes, além de oferecer elasticidade para escalar clusters sob demanda.
O que é o AWS Lake Formation e como ele auxilia na governança de dados?
O AWS Lake Formation centraliza a catalogação e o controle de acesso dos dados no Data Lake, garantindo segurança e conformidade com regulamentações como LGPD e GDPR. Ele permite configurar permissões baseadas em funções (RBAC) para acessar tabelas e colunas específicas, facilitando a aplicação de políticas de segurança detalhadas. Além disso, o Lake Formation simplifica o gerenciamento de metadados, permitindo maior agilidade na descoberta e no uso dos dados.
Como a integração com o Amazon Athena beneficia as consultas de dados?
O Amazon Athena permite executar consultas SQL diretamente no Data Lake, sem a necessidade de provisionar infraestrutura, tornando o acesso rápido e eficiente.
É possível usar o AWS Step Functions para orquestrar processos no Data Lake?
Sim, o AWS Step Functions automatiza e organiza os pipelines de dados, coordenando o fluxo entre ingestão, processamento e armazenamento em camadas.
Quais medidas de segurança são implementadas para proteger os dados no Data Lake?
São utilizadas criptografia com AWS KMS, controle de acesso granular via IAM e monitoramento com CloudTrail para auditoria e conformidade.
O Data Lake pode ser configurado para processar dados em tempo real?
Sim, com serviços como Amazon Kinesis e AWS Glue Streaming, o Data Lake suporta processamento em tempo real para grandes volumes de dados.
Como o AWS DMS facilita a ingestão de dados para o Data Lake?
O AWS DMS migra dados de bancos de dados locais ou na nuvem para o Data Lake no S3, garantindo uma transferência segura e eficiente com parquet.
Como o Data Lake suporta Machine Learning?
O Data Lake organiza dados em camadas otimizadas (Bronze, Silver e Gold), permitindo que os dados da camada Gold sejam usados diretamente no treinamento de modelos em serviços como Amazon SageMaker. Ele também integra-se a Glue DataBrew para preparação de dados e Amazon Forecast para previsões baseadas em séries temporais, garantindo que os dados estejam prontos para análises avançadas.
Fale com nossos
especialistas em Nuvem
Entre em contato conosco e descubra como podemos auxiliar sua empresa na redução de custos na Nuvem AWS. Estamos à disposição para oferecer soluções personalizadas e estratégias eficientes para otimizar seus recursos na AWS
